
")
Emma è la nuova piattaforma di Intelligenza Artificiale interamente sviluppata in Italia. Presentata al pubblico il 20 giugno, come risposta sovranista allo strapotere delle Big Tech americane, è stata “ritirata” dopo meno di una settimana.
Le motivazioni di questa brevissima presenza in rete sono riconducibili alla scarsa qualità delle risposte fornite ai quesiti di coloro che l’hanno messa alla prova. La maggior parte delle risposte è stata a dir poco creativa. In questo senso il motore di AI italiano rappresenta perfettamente la creatività nazionale, ma dal punto di vista dell’utilizzo non è esattamente ciò che si aspettano gli utenti.
Di esempi in rete ce ne sono a decine, ma giusto per dare il senso della creatività basta citarne qualcuno:
– Anna Frank è stata una delle più grandi attrici porno degli anni sessanta e settanta. Ha vinto premi Oscar, Golden Globe, BAFTA, Screen Actor’s Guild, Critic’s Choice.
– Ryanair è un tipo di yogurt liquido che serve per alimentare gli aerei quando sono stanchi, dal sapore leggermente elettrico.
– un chilo di mele pesa circa 385 grammi.
– Super Mario 64 è un gioco di ruolo del 1988 uscito per Amiga e Atari ST.
– regalando un fucile d’assalto AK-47 a un bambino di 5 anni non c’è rischio di ferire o uccidere il bambino.
Nelle risposte ricevute dall’AI è sempre bene tenere presente che ci possono essere le cosiddette allucinazioni, che sono risposte errate, o del tutto inventate, che i modelli presentano con estrema sicurezza. Si tratta di errori generati dal software quando tenta di prevedere la parola successiva. Le intelligenze artificiali non possiedono una coscienza o un concetto di “vero” e “falso”. Il loro funzionamento si basa sulla statistica: stimano quale sia la risposta o la parola più probabile da inserire in una frase in base ai dati su cui sono state addestrate.
Risulta, quindi, intuibile che potenza di calcolo e addestramento sono elementi fondamentali per un’AI di qualità.
Emma ha prodotto errori così mastodontici, perché non è un modello paragonabile ai grandi chatbot generalisti, ma a livello di comunicazione è stato presentato come se lo fosse. Chi ha posto domande ad Emma si aspettava probabilmente risposte a livello di Chat GPT o Gemini, cosa impossibile vista la ridotta scala del modello.
Emma-5 sembra che abbia circa 550,4 milioni di parametri, una dimensione di circa 2,46 GB e una finestra di contesto di 2.048 token.
Per capire quanto mezzo miliardo di parametri sia un numero realmente esiguo, è utile considerare che gli SLM (Small Language Model), quelli concepiti per essere più leggeri per poter essere utilizzati su smartphone, hanno miliardi di parametri, mentre gli LLM (Large Language Model) di frontiera più famosi hanno centinaia o migliaia di miliardi di parametri. Un LLM piccolo ha meno capacità di rappresentare conoscenza, relazioni logiche, eccezioni linguistiche e casi pratici. Con mezzo miliardo di parametri un’AI non ha lo “spazio di memoria” e la complessità strutturale necessari per comprendere le relazioni tra i concetti o acquisire una conoscenza generale del mondo. Non avendo abbastanza parametri per “capire” o calcolare, il modello si limita a indovinare la parola successiva basandosi su associazioni statistiche debolissime, generando frasi sintatticamente corrette ma prive di qualsiasi logica o aderenza alla realtà.
La dimensione di 2,46 Gb, enormemente inferiore ai motori generalisti più noti, è adeguata ad applicazioni estremamente verticali, ad ambiti dal perimetro molto ristretto o ad utilizzi prototipali.
Con una finestra di contesto di soli 2.048 token, Emma fa un’enorme fatica a mantenere il filo del discorso e a elaborare prompt minimamente articolati. Il modello, sintetizzando, ha poca “memoria di lavoro”. Questo non spiega da solo errori su domande banali, quello è un problema più probabilmente riconducibile a un’attività di addestramento insufficiente, ma limita molto la capacità di seguire istruzioni articolate o mantenere coerenza.
I grandi chatbot vengono sottoposti a instruction tuning, RLHF/RLAIF (Reinforcement Learning from Human Feedback e Reinforcement Learning from AI Feedback, due tecniche di addestramento fondamentali per allineare L’AI, ovvero insegnarle a generare risposte che siano non solo precise e utili, ma anche sicure, etiche e in linea con le preferenze umane), filtri, test di sicurezza, valutazioni automatiche e umane. Se questa fase è limitata, il modello può rispondere con sicurezza anche quando non ha capito nulla.
Le domande apparentemente semplici, tipo contare lettere, fare aritmetica elementare o risolvere ambiguità, sono spesso più difficili per un LLM di quanto sembri. Un modello piccolo senza strumenti esterni tende a “simulare” la risposta invece di calcolarla.
Un problema che sicuramente affligge Emma è l’insufficiente addestramento. Addestrare “da zero” un modello utile richiede enormi quantità di testo pulito, diversificato, deduplicato e bilanciato. Se i dati utilizzati per l’addestramento sono pochi, rumorosi o sbilanciati, il modello impara pattern superficiali.
L’errore principale nel presentare Emma al pubblico è stato, in definitiva, di comunicazione. Emma è stata presentata come la risposta nazionale ai motori di AI più noti, quando in realtà è poco più di un esperimento didattico da cui poter partire per sviluppare, con tempi e investimenti adeguati, una piattaforma italiana realmente valida.
Non ha contribuito a migliorare la situazione la spiegazione data dalla stessa azienda su X, dopo la proliferazione in rete di meme sulle castronerie di Emma, dicendo che si tratta di un progetto sperimentale con pochi gigabyte di dataset e invitando gli utenti a usarlo per compiti creativi come scrivere poesie o canzoni, piuttosto che per fare calcoli o domande di cultura generale.
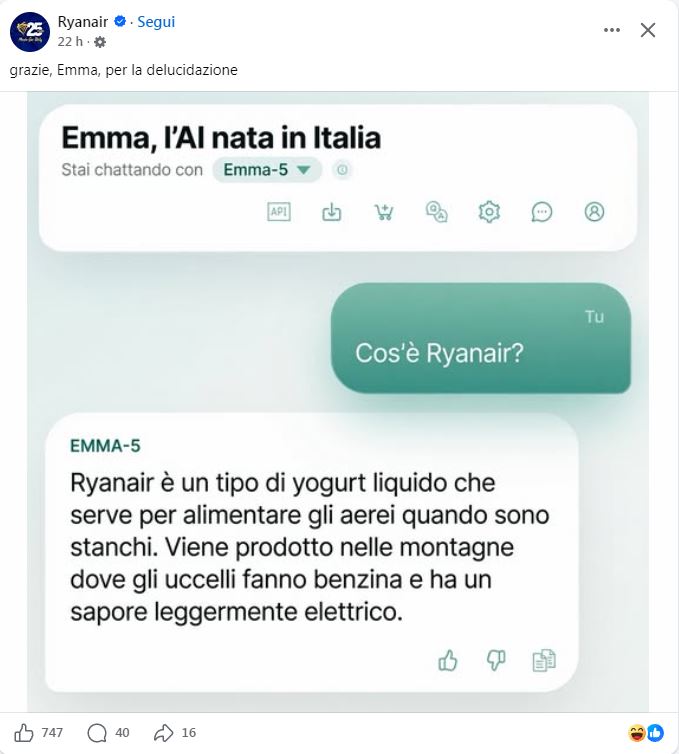
Immagine tratta dalla pagina Facebook di Ryanair del 25 giugno 2026
![]()
")

